
Proteome and Phosphoproteome Turnover Atlas in Mice – Paper Published In Cell Journal with 45.5 IF

Dr Abhijit Dasgupta, Assistant Professor from the Department of Computer Science and Engineering, has published his breakthrough research article titled “Turnover Atlas of Proteome and Phosphoproteome Across Mouse Tissues and Brain Regions” in the nature index journal Cell having an impact factor of 45.5.
Abstract
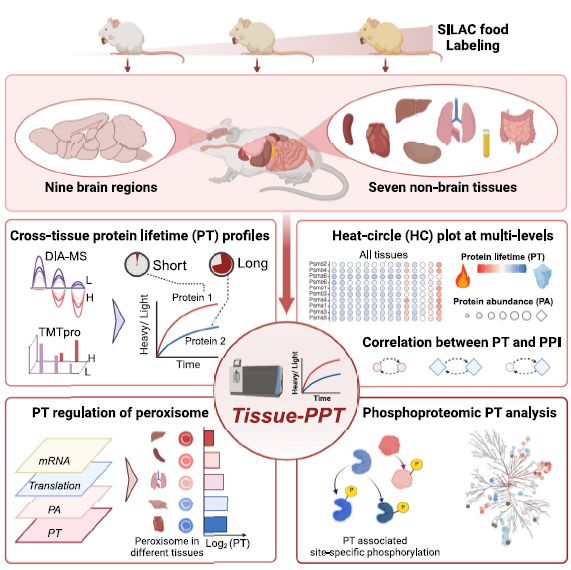
This study presents a comprehensive in vivo atlas of protein and phosphoprotein turnover across 16 mouse tissues and brain regions, integrating advanced mass spectrometry with stable isotope labeling. By mapping over 11,000 proteins and 40,000 phosphosites, the study reveals tissue-specific patterns of protein lifetimes, correlating them with abundance, function, and protein-protein interactions (PPI). It highlights how phosphorylation regulates protein stability and how turnover is linked to peroxisome function, ubiquitination, and neurodegeneration-associated proteins such as Tau and α-synuclein. This high-resolution resource enhances our understanding of proteostasis and dynamic protein regulation, providing new insights into tissue-specific physiology and disease mechanisms.
Explanation of the Research in Layperson’s Terms
All cells in the body continuously make and break down proteins. The balance of these processes—called protein turnover—is vital for keeping tissues healthy. But until now, scientists didn’t have a clear, detailed map of how protein turnover works across different tissues and brain regions.
In this study, researchers used advanced techniques to measure how long thousands of proteins and their phosphorylated (chemically modified) versions last in 16 parts of the mouse body. They discovered that some proteins, especially in the brain and heart, live much longer than others. They also found that proteins interacting with each other often have similar lifespans, and that specific chemical modifications like phosphorylation can either stabilize or destabilize key proteins—such as those involved in Alzheimer’s and Parkinson’s diseases.
The team created an online tool that lets other scientists explore this rich dataset. The findings can help understand tissue function better and may lead to new ways to treat diseases by targeting protein stability.
Practical Implementation/ Social Implications of the Research
Practical Implementation:
This turnover atlas provides a foundational resource for drug development and tissue-specific disease research. It supports AI-driven approaches to predict protein dynamics, aids in identifying long-lived disease-related proteins, like Tau and α-synuclein, and enhances biomarker discovery for neurodegenerative and metabolic diseases. The integrated tool Tissue-PPT allows researchers to explore and analyze protein lifespan and phosphorylation patterns across tissues.
Social Implications:
Understanding how proteins behave differently across tissues could help create more precise therapies for complex diseases such as Alzheimer’s, Parkinson’s, and cardiomyopathies. The dataset empowers researchers globally to explore protein turnover without relying heavily on animal experiments, advancing ethical and efficient biomedical research.
Collaborations
- Yale University School of Medicine, CT, USA
- St. Jude Children’s Research Hospital, TN, USA
- University Medical Center Göttingen, Germany
- University of Trieste, Italy
- West China Hospital, Sichuan University, China
Future Research Plans
The next phase will focus on AI-driven modeling of site-specific phosphorylation turnover in relation to disease phenotypes, using the Tissue-PPT dataset as a foundation. This includes integrating proteomics, phosphoproteomics, and transcriptomic data to refine our understanding of proteome regulation. Special attention will be given to how phosphorylation modulates the stability of neurodegenerative disease proteins and the development of targeted dephosphorylation therapeutics (e.g., PhosTACs).
This research aims to inform personalised interventions and identify novel therapeutic targets by understanding how tissue-specific protein lifespans are regulated under physiological and pathological conditions.
- Published in CSE NEWS, Departmental News, News, Research News
Patent on Invisible Watermarking In Social Media Images
 Professors, Dr Manikandan V M and Mr Shaik Johny Basha from the Department of Computer Science and Engineering along with their B.Tech. students Ms Aafrin Mohammad and Ms Rohini Sai Pasupula have published the patent titled, “A System And A Method For Adaptive Invisible Watermarking In Social Media Images.” Their patent introduces a novel method for securing photo downloads, ensuring that any unauthorised use of the images can be traced back to its original source if tampered with.
Professors, Dr Manikandan V M and Mr Shaik Johny Basha from the Department of Computer Science and Engineering along with their B.Tech. students Ms Aafrin Mohammad and Ms Rohini Sai Pasupula have published the patent titled, “A System And A Method For Adaptive Invisible Watermarking In Social Media Images.” Their patent introduces a novel method for securing photo downloads, ensuring that any unauthorised use of the images can be traced back to its original source if tampered with.
Abstract:
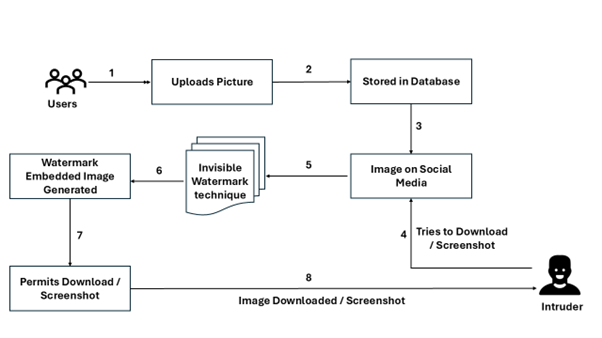
The invention presents a System and Method for Adaptive Invisible Watermarking in Social Media Images to enhance digital privacy and copyright protection. The proposed system integrates advanced invisible watermarking technology to embed unique, imperceptible metadata into images. When users attempt to download or screenshot images from social media, the system automatically adds a hidden watermark containing identifying details such as IP address, Date, Time, and Location. This ensures that any unauthorized use of the images can be traced back to the source. By combining image processing, data encryption, and digital rights management, this system provides a robust solution for protecting online images without affecting their visible quality.
Explanation in Layperson’s Terms:
In today’s digital world, people frequently share personal photos on social media, but there is very little protection against unauthorized downloads or screenshots. Once an image is copied, there is no way to track who took it or where it is being used. Through their invention, the team solves this problem by embedding a hidden watermark in images without changing how they look. This hidden watermark automatically adds invisible information such as the IP address, location, date, and time of the user who downloads or screenshots the image. This means that if the image is misused or shared without permission, it can be traced back to the source. By combining image editing techniques, encryption, and digital security, they ensure that people’s photos remain safe and trackable online. Hence, the invention provides a new way to protect privacy and copyright while allowing users to engage freely on social media.
Practical and Social Implications:
The proposed Adaptive Invisible Watermarking System can be practically implemented using a combination of image processing algorithms, digital watermarking techniques, and cloud-based metadata storage. Below are the key steps in its real-world application:
- Integration with Social Media Platforms: The system can be embedded in social media platforms like Facebook, Instagram, X, and LinkedIn to automatically apply invisible watermarks containing metadata (IP address, timestamp, location, etc.) to uploaded images without altering their visual appearance.
- Automatic Watermarking During Downloads or Screenshots: When a user downloads or screenshots an image, the system automatically applies a second layer of invisible watermarking that includes identifying information of the downloader, ensuring every image copy has a unique identifier for traceability.
- Forensic Tracking and Copyright Protection: If an unauthorized user shares or misuses an image, the embedded watermark can be extracted using forensic tools to trace back to the original downloader, aiding in copyright enforcement, digital rights management (DRM), and legal actions against unauthorized distribution.
- Security and Privacy Features: The system can implement blockchain technology to securely log watermark data, ensuring tamper-proof verification, and provides users the option to control watermarking settings based on their privacy preferences.
- Prevention of Image Misuse and Cybercrime: The system reduces cases of identity theft, deepfake creation, and revenge porn by enabling traceability of unauthorized image usage, helping protect individuals from stalking and cyber harassment.
- Enhanced Digital Privacy and Ownership Rights: Users are empowered to maintain ownership of their photos even after sharing them on social media, encouraging ethical content sharing while discouraging unauthorized downloads.
- Impact on Content Creators and Businesses: Artists, photographers, and digital content creators can protect their work from theft or unauthorized republishing, while influencers and businesses can safeguard their brand assets and prevent content duplication.
- Legal and Ethical Implications: The system encourages social media companies to take responsibility for user content protection and supports law enforcement in tracking down offenders involved in image-based cybercrimes.
Future Research Plans:
- AI-Powered Watermarking and Deep Learning for Image Security
- Blockchain-Based Digital Rights Management (DRM) for Image Ownership
- Cross-Platform Compatibility & Social Media API Integration
Link to publication: https://search.ipindia.gov.in/IPOJournal/Journal/Patent
- Published in CSE NEWS, Departmental News, News, Research News
Revolutionising Cardiac Diagnostics and Real-time Health Monitoring

Dr Manjula R, Assistant Professor, Department of Computer Science and Engineering, and Dr Anirbhan Ghosh, Assistant Professor, Department of Electronics and Communication Engineering, has recently had their patent published titled “A System for Analyzing Electromagnetic Wave Scattering Path Loss in a Tissue and a Method Thereof” with Application no: 202541001730.
The faculty duo has revolutionised cardiac diagnostics and real-time health monitoring through their invention. This innovative system analyses electromagnetic wave scattering in biological tissues, using terahertz (THz) frequencies to optimise nanosensor communication and path loss analysis. By leveraging cutting-edge technology, it enables advanced biomedical devices for precise physiological monitoring and safer, more reliable in-vivo communication systems. A step forward for heart health and medical breakthroughs, this invention bridges the gap between technology and life-saving healthcare solutions.
- Published in CSE NEWS, Departmental News, ECE NEWS, News, Research News
Dr Abhijit Dasgupta Publish his Research on Alzheimer’s disease (AD) in Nature Index Journal

Dr Abhijit Dasgupta, Assistant Professor from the Department of Computer Science and Engineering, has published his groundbreaking research on using deep proteomics to analyse Alzheimer’s disease (AD) models in mice and comparison with human AD protein alterations. He has published the paper titled “Human-mouse proteomics reveals the shared pathways in Alzheimer’s disease and delayed protein turnover in the amyloidome” as one of the first authors in the Nature Index journal Nature Communications, having an impact factor of 14.7.
Abstract
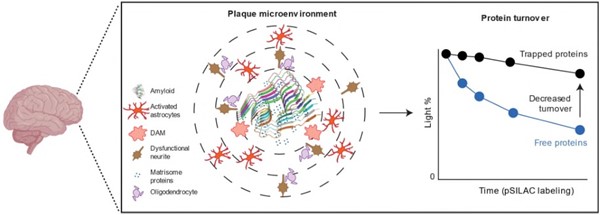
Alzheimer’s disease (AD) is a complex neurodegenerative disorder characterized by amyloid-beta (Aβ) plaques and tau tangles. This study presents a comprehensive proteomic and phosphoproteomic analysis of multiple AD mouse models, comparing their molecular pathways with human AD data to evaluate their translational relevance. Using deep proteomics, the study identifies shared and distinct protein alterations across amyloidosis models (5xFAD, APP-KI), tauopathy models (3xTG), and splicing dysfunction models (BiG). While these models collectively replicate 42% of human AD protein alterations, amyloid formation significantly delays protein turnover in the amyloidome, contributing to proteome-transcriptome discrepancies. Proteomic and turnover analysis highlight the accumulation of proteins such as ApoE, CLU, and HTRA1, implicating lysosomal and autophagic dysfunction. These findings underscore the importance of protein homeostasis in AD pathology and provide a multi-omics resource for selecting appropriate mouse models for specific disease mechanisms.
Explanation of the Research in Layperson’s Terms
Alzheimer’s disease (AD) is a brain disorder that affects memory and thinking ability. Scientists know that AD is caused by harmful clumps of proteins—called amyloid-beta (Aβ) plaques—that build up in the brain. However, studying AD in humans is challenging, so researchers often use mice with genetic modifications that mimic the disease.
This study looks at different types of AD mouse models and compares their brain protein changes to those seen in humans with Alzheimer’s. The researchers analysed thousands of proteins to understand how the disease progresses, how mouse models reflect human AD, and what biological processes might be involved.
One key finding is that in both mice and humans, the buildup of Aβ plaques slows down the normal breakdown and recycling of certain proteins. This means that some proteins accumulate in the brain not just because they are being produced in excess but also because they are not being cleared efficiently. This could explain why some aspects of AD develop over time.
The study also shows that while current mouse models capture some aspects of human AD, none of them fully replicate the disease. However, when different models are combined, they represent a larger portion of the changes seen in human AD. This research provides valuable insights into how AD develops and helps scientists choose the right mouse models for studying different parts of the disease. It also highlights potential targets for future treatments focused on restoring protein balance in the brain.
Practical Implementation/Social Implications of the Research
Practical Implementation
This research helps improve Alzheimer’s disease (AD) drug development by identifying key proteins involved in disease progression. It aids in selecting better animal models for testing treatments, enhances early diagnosis through biomarkers, and supports AI-driven modelling of disease progression. The findings could lead to therapies that improve protein clearance, slowing AD progression.
Social Implications
With AD cases rising globally, this study has significant public health and economic impacts. It could reduce caregiver burden, lower healthcare costs, and improve the quality of life for ageing populations. Additionally, it encourages ethical advancements in research by promoting better human-relevant models and minimising reliance on animal testing.
Collaborations
- St. Jude Children’s Research Hospital, Memphis, TN, USA.
- University of Tennessee Health Science Center, Memphis, TN, USA
- Yale University School of Medicine, New Haven, CT, USA
Future Research Plans
The future focus will be on AI-driven modelling of temporal proteomics to understand Alzheimer’s Disease (AD) progression and identify therapeutic targets. By integrating mass spectrometry-based proteomics, machine learning, and protein turnover analysis, the goal is to bridge transcriptome-proteome discrepancies and uncover key regulatory pathways.
The research aims to develop cost-effective AI-based diagnostics for AD and cardiomyopathies, utilizing multi-omics integration for early detection and personalized treatments. This approach will contribute to precision medicine and scalable healthcare solutions for a broader impact.
- Published in CSE NEWS, Departmental News, News, Research News
Tech Wizards Claim South Zone Title at Nation Building Competition

In a world where the potential of GenZs is often questioned, two of our students, Md. Hadi Mahmood and Md Ahmed Raza Khan have proven that their engagement can deliver meaningful change. These III-year BTech CSE students have showcased an inspiring display of their intellect and innovative prowess at the Nation Building Case Study Competition, an annual event that aligns with the “Viksit Bharat” initiative led by Hon’ble Prime Minister Shri. Narendra Modi, inviting college teams from across the nation to develop creative strategies aimed at transforming India into a developed country by 20247.
Here’s an excerpt of their interview:
1. What was the competition/event about?
The NationBuilding Case Study Competition is an annual event organised to inspire young college students to contribute to India’s development by addressing critical national issues. Participants engage in a 2-month-long journey involving multiple rounds, including an online quiz, presentation submissions, zonal finals, and the national finals in New Delhi. The competition is judged by a distinguished panel of experts in the given domain.
This year’s competition, NationBuilding Case Study Competition 2025, focused on the problem statement of identifying the gaps in India’s sports environment. Participants were tasked with studying the sports systems of other countries, analysing their strengths, and drafting a model to achieve India’s vision of hosting and winning 100 medals in the Olympics by 2036. This theme aimed to encourage innovative solutions to elevate India’s standing in global sports and align with the broader goal of nation-building.
2. What place did you secure?
We secured the 1st rank in the South Zone during the third round of the competition, competing against teams from multiple prestigious institutions. This achievement has advanced us to the national finals, where we will compete against the top 2 teams from each of the six zones: North, South, East, North East, West, and Central.
3. How did you find out about the competition?
We discovered this opportunity on the Unstop platform. The NationBuilding Case Study Competition is widely recognised and attracts thousands of teams annually, making it a highly sought-after event for students across India.
4. Who were your competitors
In the South Zone, we competed against 10 teams from premier institutions. The competition was intense, as participants brought innovative solutions to the table, reflecting the high level of talent and dedication among the youth.
5. Your feelings on advancing this far and future aspirations.
We are excited to have advanced to the national finals. Competing against the best teams from across the country is both a challenge and an opportunity to showcase our strategic thinking and problem-solving skills. This competition has allowed us to apply our skills & knowledge to real-world issues, which has been incredibly rewarding. We look forward to the final round and hope to contribute meaningfully to the vision of a developed India.
- Published in CSE NEWS, Departmental News, News, Students Achievements
Revolutionising Cardiac Health Monitoring with Cutting-edge Innovation

The research team consisting of Dr Manjula R, Assistant Professor from the Department of Computer Science and Engineering and her students, Mr Adi Vishnu Avula, Mr Abdul Jawad Khan, Mr Chiranjeevi Thota and Ms Kavyanjali Munipalle has published their patent titled “System For Determining And Predicting Scattering Coefficients Of Myocardium Tissue In Near-Infrared-Band For In-Vivo Communications” in the Indian Patent Office with the Application no: 202441090535.
Their research harnesses the power of machine learning and near-infrared (NIR) technology to analyse myocardium tissue with unmatched precision. By predicting scattering coefficients using advanced models like Gradient Boosting and Artificial Neural Networks (ANN), this breakthrough enables non-invasive diagnostics, early detection of heart conditions, and enhanced medical imaging. From 6G-enabled smart hospitals to regenerative medicine, this technology is set to transform healthcare.
With this groundbreaking invention, Dr Manjula and her research team pave the way for the future of connected, intelligent cardiac care!
- Published in CSE NEWS, Departmental News, News, Research News
A Blockchain-Based Peer Tutoring Platform
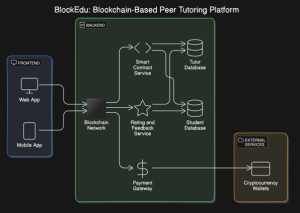
 In a rapidly changing educational landscape, innovative solutions are key to enhancing learning experiences. Ms Naga Sravanti’s patent on A System for Implementing a Peer Tutoring Platform, introduces a blockchain-based peer tutoring platform designed to tackle challenges in traditional education.
In a rapidly changing educational landscape, innovative solutions are key to enhancing learning experiences. Ms Naga Sravanti’s patent on A System for Implementing a Peer Tutoring Platform, introduces a blockchain-based peer tutoring platform designed to tackle challenges in traditional education.
As we explore the implementation and societal implications of this platform, its potential to democratise education and create valuable connections among learners worldwide becomes evident. Join us in examining this innovative approach and its promising future research directions.
Abstract
This research presents a blockchain-based peer tutoring platform designed to enhance the quality and accessibility of education. By utilising blockchain’s decentralized and transparent features, the system ensures secure transactions, reliable certification, and the equitable management of peer tutoring activities. The platform aims to foster trust among users by recording all interactions and achievements on an immutable ledger, addressing critical challenges like data manipulation, lack of accountability, and accessibility issues in traditional education systems.
Explanation in Layperson’s Terms
Imagine a platform where students can teach and learn from each other without worrying about unfair practices or lack of credibility. This system uses blockchain, a technology that keeps records safe and transparent so that everyone can trust it. For instance, when a student tutors someone else, the system records this in a way that no one can alter. Certificates issued for achievements are also tamper-proof, making them reliable for future use. It’s like having a digital notebook that no one can tear a page from or erase anything written in it. This platform creates a fair and secure space where students and educators can collaborate effectively.
Practical Implementation and Social Implications
The peer tutoring platform has immense potential to revolutionise education:
Equity in Education: Students from diverse backgrounds can access quality tutoring at affordable costs or through a mutual exchange of knowledge.
Trust and Credibility: Blockchain’s secure system ensures that all records of learning and certifications are genuine and cannot be tampered with.
Recognition of Effort: Tutors can build verified portfolios showcasing their expertise and contributions, which can be used for job opportunities or further education.
Global Collaboration: Learners and educators worldwide can connect, exchange knowledge, and grow together, breaking geographical barriers.
Collaborations
This research has benefited from partnerships with educational institutions, blockchain developers, and organizations promoting innovative learning methodologies. Collaborators include academic peers at SRM University-AP and technical support from blockchain technology firms specializing in educational applications.
Future Research Plans
Building on this work, the following directions will be explored:
- Gamified Learning: Introducing game-like features to make learning more engaging and interactive.
- AI-Driven Personalization: Integrating AI to recommend the best tutors and resources for individual learners based on their unique needs.
- Scalability: Expanding the platform to accommodate millions of users globally without compromising speed or security.
- Real-World Deployments: Partnering with schools, universities, and governments to implement the system on a larger scale, bringing tangible benefits to communities.
- Published in CSE NEWS, Departmental News, News, Research News
Patent on SQL Free Database Interaction
This research, by Dr Ashu Abdul, Assistant Professor and research scholar Ms Surya Samantha Beri along with forth-year student, Mr Jakkampudi Venkatasubbaiah from the Department of Computer Science and Engineering explores a framework designed to help users retrieve and analyse data without requiring any Structured Query Language (SQL) knowledge. The patent titled, “System and Method for Generating Structured Queries from Natural Language Inputs , with application no: 202441096460 is particularly relevant as it enables individuals, like a car dealer seeking sales insights, to interact with their databases using everyday language. Such accessibility underscores the importance of this research in democratising data access for all users.
Abstract:
This project is centred around creating a framework that translates user queries into SQL statements and retrieves results without requiring any SQL knowledge from the user. By delving into the workings of various RDBMS systems, with a special focus on MySQL, I developed a solid understanding of database architecture and how databases are engineered for optimized performance. This knowledge was critical in designing a system that can seamlessly interact with any given database, analyse it, and provide relevant results in response to user input.
About the Framework:
This framework is intended to convert the user queries into SQL statements and attain the results from the database without intervention of SQL coding. Every time writing multiple SQL commands to apply filters, commands, and extracting data is time-consuming and requires having knowledge of SQL knowledge. This project is intended to analyze a database and answer the questions that are related to a particular database without writing SQL commands.
Explanation in Layperson’s Terms:
In-General we rely on programmers who are efficient in programming SQL for finding the insights from the database which are related to business or information. So, Laymen cannot access data without knowing SQL this project makes it possible. Assume, Mr. A a car dealer owns a showroom has a software dealing with his Business he wants to access his data and get insights for understanding the sales. Now he is not familiar with using SQL so he relies on someone for that or opens software and applies multiple filters to analyze his data. But What if he can use a chatbot and get solutions for all his questions from his database?
Mr.A can get conclusions from his data within no-time that thought represents this entire project.
What are the use cases of this framework to a layman?
Laymen interaction with the database for understanding their data. Reducing the requirement to understand and search for the filters in the front-end. Faster data extraction from the database. Generating the results based on user queries in natural language without SQL coding. Elimination of time and efforts required for writing SQL Commands or applying filters. Understanding data gets easier for engineers as well as unknown data can be understood easily.
Practical Implementation:
This project has been successfully integrated into several existing real-time applications, enabling precise identification of data locations. By fine-tuning and enhancing our algorithms, we have achieved significant improvements in accuracy. In practical terms, users can effortlessly explore and comprehend their data.
Furthermore, extensive testing across databases of varying sizes has demonstrated the project’s ability to deliver significant and well-structured results.
Future Enhancements:
Incorporating Natural Language Processing (NLP) to process and respond to queries in users’ native languages, including speech-to-text capabilities.
Facilitating the generation of dynamic reports in various formats such as PDFs and Excel sheets.
Expanding compatibility to support additional database systems like Oracle, PostgreSQL, and NoSQL models.
Enabling data extraction and analysis from Excel sheets and CSV files.
- Published in CSE NEWS, Departmental News, News, Research News
Patent on SQL Free Database Interaction
 This research paper, by Dr Ashu Abdul, Assistant Professor and research scholar Ms Surya Samantha Beri along with fourth-year student, Mr Jakkampudi Venkatasubbaiah from the Department of Computer Science and Engineering explore a framework designed to help users retrieve and analyse data without requiring any Structured Query Language (SQL) knowledge. The paper titled, “System and Method for Generating Structured Queries from Natural Language Inputs“, is particularly relevant as it enables individuals, like a car dealer seeking sales insights, to interact with their databases using everyday language. Such accessibility underscores the importance of this research in democratising data access for all users.
This research paper, by Dr Ashu Abdul, Assistant Professor and research scholar Ms Surya Samantha Beri along with fourth-year student, Mr Jakkampudi Venkatasubbaiah from the Department of Computer Science and Engineering explore a framework designed to help users retrieve and analyse data without requiring any Structured Query Language (SQL) knowledge. The paper titled, “System and Method for Generating Structured Queries from Natural Language Inputs“, is particularly relevant as it enables individuals, like a car dealer seeking sales insights, to interact with their databases using everyday language. Such accessibility underscores the importance of this research in democratising data access for all users.
Abstract:
This project is centred around creating a framework that translates user queries into SQL statements and retrieves results without requiring any SQL knowledge from the user. By delving into the workings of various RDBMS systems, with a special focus on MySQL, I developed a solid understanding of database architecture and how databases are engineered for optimized performance. This knowledge was critical in designing a system that can seamlessly interact with any given database, analyse it, and provide relevant results in response to user input.
About the Framework:
This framework is intended to convert the user queries into sql statements and attain the results from the database without intervention of sql coding. Every time writing multiple SQL commands to apply filters, commands, and extracting data is time-consuming and requires having knowledge of SQL knowledge. This project is intended to analyze a database and answer the questions that are related to a particular database without writing sql commands.
Explanation in Layperson’s Terms:
In-General we rely on programmers who are efficient in programming SQL for finding the insights from the database which are related to business or information. So, Laymen cannot access data without knowing SQL this project makes it possible. Assume, Mr. A a car dealer owns a showroom has a software dealing with his Business he wants to access his data and get insights for understanding the sales. Now he is not familiar with using SQL so he relies on someone for that or opens software and applies multiple filters to analyze his data. But What if he can use a chatbot and get solutions for all his questions from his database?
Mr.A can get conclusions from his data within no-time that thought represents this entire project.
What are the use cases of this framework to a layman?
Laymen interaction with the database for understanding their data. Reducing the requirement to understand and search for the filters in the front-end. Faster data extraction from the database. Generating the results based on user queries in natural language without sql coding. Elimination of time and efforts required for writing SQL Commands or applying filters. Understanding data gets easier for engineers as well as unknown data can be understood easily.
Practical Implementation:
This project has been successfully integrated into several existing real-time applications, enabling precise identification of data locations. By fine-tuning and enhancing our algorithms, we have achieved significant improvements in accuracy. In practical terms, users can effortlessly explore and comprehend their data.
Furthermore, extensive testing across databases of varying sizes has demonstrated the project’s ability to deliver significant and well-structured results.
Future Enhancements:
Incorporating Natural Language Processing (NLP) to process and respond to queries in users’ native languages, including speech-to-text capabilities.
Facilitating the generation of dynamic reports in various formats such as PDFs and Excel sheets.
Expanding compatibility to support additional database systems like Oracle, PostgreSQL, and NoSQL models.
Enabling data extraction and analysis from Excel sheets and CSV files.
- Published in CSE NEWS, Departmental News, News, Uncategorized
ACM Winter School 2024: A Platform for Innovation
 The ACM Winter School 2024, organised by the Department of Computer Science, was aimed to enhance advanced learning in the field of computing. This prestigious programme successfully attracted participants from across India, representing 22 eminent institutions, including notable names like IIT Delhi, IIT Gandhinagar, and IIT Hyderabad.
The ACM Winter School 2024, organised by the Department of Computer Science, was aimed to enhance advanced learning in the field of computing. This prestigious programme successfully attracted participants from across India, representing 22 eminent institutions, including notable names like IIT Delhi, IIT Gandhinagar, and IIT Hyderabad.
The inaugural session, was graced by distinguished academic figures such as Prof. Nibaran Das from Jadavpur University and Prof. C V Tomy, the Dean of the School of Engineering and Sciences. The faculty coordinators, Dr Priyanka Singh, Dr Ajay B, Dr Ravi Kant Kumar, and Dr Niladri Sett, played significant roles in facilitating the event.
During the opening remarks, Dr Ajay B, who serves as an Assistant Professor and faculty coordinator, emphasised the importance of creating platforms that inspire innovative thinking and empower students with fresh, out-of-the-box ideas. His perspective resonated with the overarching goals of the Winter School to cultivate cre ativity and collaboration among the participants.
ativity and collaboration among the participants.
Dr Priyanka Singh provided a comprehensive overview of the programme’s objectives, setting the tone for the enriching experiences that lay ahead. Following her, Prof. C V Tomy addressed the audience, underscoring the significance of such events in offering new insights and facilitating networking opportunities. He praised the organising team for their commitment to making this initiative a reality and highlighted its potential impact on the academic journeys of the participants.
With a dynamic lineup of sessions led by experts from various parts of the country, the ACM Winter School delivered a transformative learning experience. This gathering promotes collaboration and knowledge exchange, aiming to foster a deep understanding of critical computing topics among attendees.
Adding to the programme’s rich content, Dr Abhishek Singh was recognised as the esteemed resource person for the Winter School. His extensive expertise and invaluable insights have significantly enriched the experience, inspiring participants to engage in innovative thought. The gratitude expressed by the faculty coordinators—Dr Priyanka Singh, Dr Ajay B, and Dr Ravi Kant Kumar—reflects the lasting impact his contributions have made on all attendees.
The ACM Winter School 2024 promises to be a milestone event, equipping participants with knowledge and skills that will undoubtedly resonate in their academic and professional pursuits.





- Published in CSE NEWS, Departmental News, News